Table of Contents
What is a robots.txt?
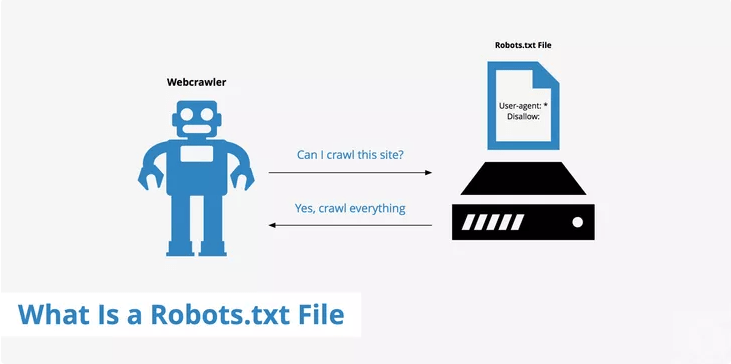
A robots.txt file is a text file that defines what parts of the domain can be crawled through the web crawler and what is not. Additionally, the robots.txt file may contain a link to the XML-sitemap. With Robots.txt, individual files in the directory, complete directories, subdirectories, or entire domains can be excluded from crawling. Learn about a quality score in Google Ads.
robots-txt Data is stored on the root domain. This is the first document that was accessed when visiting the BOT website. Bots of big search engines like Google and Bing follow the instructions. Otherwise, there is no guarantee that a bot will meet the requirements of robots.txt.
What is robots.txt used for?

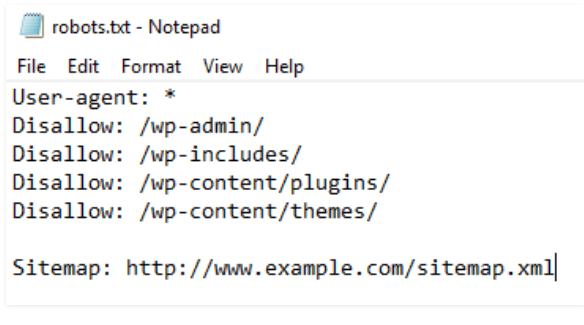
robots.txt helps the search engine to control the crawl of robots. Also, the robots.txt file may contain a reference to the XML sitemap to inform crawlers about the URL structure of the website. Individual subpages can be excluded from indexing using the meta tag label robot and, for example, the value index. Learn about Google page RPM.
If your web page is blocked by a robots.txt file, its URL may still appear in the search results, but the search result will not contain a description. Image files, video files, PDFs, and other non-HTML files are excluded. If you see this search result for your page and want to fix it, remove the robots.txt entry that blocks the page. If you want to completely hide the page from the search, use another method.
Use the robots.txt file to manage crawl traffic and prevent image, video, and audio files from appearing in Google search results. This does not prevent other pages or users from linking to your image/video/audio file.
If you feel that pages loaded without these resources will not be significantly affected by the damage, you can use the Robots .text file to block resource files such as insignificant images, scripts, or style files. However, if these resources are not available, Google crawlers’ pages may be difficult to understand, do not block them, otherwise, Google will not do a good job of analyzing pages that rely on those resources.
The limitations of the Robots.txt file
Before creating or editing a robots.txt file, you should be aware of the limitations of this URL blocking method. Depending on your goals and situation, you may want to consider other mechanisms to ensure that your URLs are not searchable on the web.
1. The Robots.txt specification may not be supported by all search engines.
Commands from robots.txt files cannot execute crawler behavior on your site; Following them is up to the crawler. While Googlebot and other popular web crawlers follow the instructions in the robots.txt file, other crawlers cannot. Therefore, if you want to protect information from web crawlers, it is a good idea to use other hacking methods such as password-protected private files on your server.
2. Different crawlers interpret the syntax differently.
Although popular web crawlers follow the instructions in the robots.txt file, each crawler’s instructions can be interpreted differently. Some people may not understand the specific instructions so they must know the proper syntax to fix different web crawlers.
3. An unapproved page in robots.txt can be indexed even if it is linked to other sites.
Although Google does not crawl or index content that is blocked by the robots.txt file, we can find and index unacceptable URLs that link to other places on the web. As a result, other publicly available information, such as the URL address and the anchor text in the link to the page, may still appear in Google search results.
To properly prevent your URLs from appearing in Google search results, password-protect files on your servers, use noindex meta tags or response titles or remove the page altogether.
Hope! You find this article useful. Don’t forget to share, subscribe and leave comments. Thank You.




6 Comments
Kim Lee
Good helpful information
inamdurrani60
Thanks, Kim Lee for your response
Xavi
Nice good information. Really useful
inamdurrani60
Thank You avi
Jay
Good, nice, informative and thanks.
inamdurrani60
Thanks a lot Jay